C#에서는 내장 클래스인 string, int, double 등을 포함한 모든 클래스 object를 상속받기 때문에 new 키워드를 사용해서 객체를 생성할 수 있다.
int n = new int();
string s = new string();
MyStruct structInstance = new MyStruct();
MyClass classInstance = new MyClass();
하지만 내장 클래스들은 구조체로 정의되어 있기 때문에 구조체 변수를 생성할 때 new를 사용하지 않고 객체를 바로 생성할 수 있다.
int n = 0;
float f = 1.0f;
string의 경우 .Net에서 특별히 내부적으로 string literal로 정의되어 있는데 때문에 일반적인 참조 타입과는 다르게 직접 변수를 할당하여 객체가 생성이 가능하다.
* string literal : 문자열 상수는 소스 코드 상에 고정된 문자열 값이다.
Inherit
new 키워드는 상속과 관련해서도 사용이된다.
상속 관계에 있는 클래스에서 메서드, 프로퍼티, 이벤트 등의 멤버를 재정의할 때 사용되는데 일반적으로 멤버의 재정의에는 override 키워드를 사용하지만 new키워드를 통해서도 멤버의 재정의가 가능하다.
class BaseClass
{
public void Print()
{
Console.WriteLine("Base class");
}
}
class DerivedClass : BaseClass
{
public new void Print()
{
Console.WriteLine("Derived class");
}
}
여기서 new 키워드를 사용하여 재정의된 메서드는 부모 클래스에서 정의된 멤버와 자식 클래스에서 정의된 멤버가 모두 유지되는데 이는 덮어쓰는 override와 다르게 두 개의 멤버가 서로 다른 것으로 재정의된 메서드는 부모 클래스의 멤버와는 관계가 없는 새로운 멤버로 취급된다.
DerivedClass obj = new DerivedClass();
obj.Print();
// "Derived class" 출력
BaseClass obj = new DerivedClass();
obj.Print();
// "Base class" 출력
운영체제는 컴퓨터 시스템의 CPU, 메모리, 입출력 장치, 저장 장치 등의 자원을 효율적으로 관리하고 다른 소프트웨어나 사용자가 이용할 수 있도록 관리하는 인터페이스 역할을 하는 소프트웨어를 말한다.
Resource Management
자원관리, 운영체제는 컴퓨터의 자원을 효율적으로 관리하고 할당하는 역할을 한다.
대표적인 자원으로는 CPU, 메모리, 저장장치, 입출력 장치가 있다.
CPU
프로세스 스케줄링을 통해 CPU 자원을 할당하고 여러 프로세스 간의 경쟁 상황을 해결한다.
CPU를 효율적으로 사용하기 위해 실행 중인 여러 프로세스들 사이에서 CPU의 사용권을 어떻게 배분할지 결정하여 CPU의 사용률을 높이고 응답 시간을 최소화하며 프로세스의 우선순위를 지정하여 경쟁 상황 해결 및 효율적인 시스템 동작을 유지한다.
스케줄링 알고리즘에는 FCFS, SJF, Priority Scheduling, Round-Robin Scheduling 등이 있다.
FCFS, First Come First Served
프로세스 스케줄링의 가장 간단한 형태 중 하나이다.
준비 큐에 도착한 순서대로 프로세스를 처리하는 방식으로 매우 직관적이기 때문에 구현이 간단하지만 실행 시간이 긴 프로세스가 먼저 도착하면 그 이후에 도착한 짧은 실행 시간을 가진 프로세스들이 대기 시간이 길어지기 때문에 평균 대기 시간과 평균 반환 시간이 크게 증가할 수 있는 문제가 있다.
* Average Waiting Time : 평균 대기 시간, 프로세스가 대기하는 시간의 평균값
* Average Turnaround Time : 평균 반환 시간, 프로세스가 큐에서 대기하고 CPU를 사용하는 시간의 합의 평균값
* 일반적으로 두 지표가 작을수록 좋은 스케줄링 알고리즘으로 판단한다.
먼저 도착한 프로세스가 먼저 실행되기 때문에 CPU를 먼저 사용하는 프로세스는 대기 시간이 짧고, 나중에 사용하는 프로세스는 대기 시간이 길어진다. 따라서 평균 대기 시간과 평균 반환 시간은 프로세스 도착 순서에 따라 크게 달라진다. 또한 FCFS는 선점형 스케줄링이 아니기 때문에 한 번 시작된 프로세스는 CPU를 반환하기 전까지 계속 실행된다. 따라서 이 알고리즘은 대화형 시스템과 같이 응답 시간이 중요한 시스템에서는 적합하지 않다.
SJF, Shortest Job First
다음에 실행할 프로세스를 선택할 때 CPU Burst Time이 가장 짧은 프로세스를 선택하는 알고리즘이다.
CPU 버스트 시간이 짧은 작업이 먼저 실행되면 해당 작업이 빠르게 완료되면 자원을 빨리 반환할 수 있고 다른 작업도 빠르게 실행될 수 있기 때문에 때문에 평균 대기 시간을 줄일 수 있다는 장점이 있다.
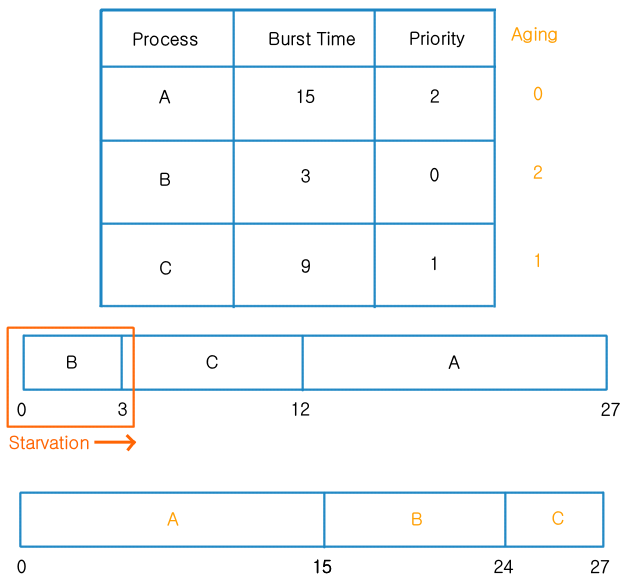
Priority Scheduling
FCFS와 SJF 알고리즘은 일괄적으로 대결에서 작업을 처리하기 때문에 일부 작업이 너무 오래 실행되거나 대기하는 경우 다른 작업들은 계속해서 대기열에 쌓이게 되는 문제가 있다. 이렇게 필요한 만큼의 CPU 자원을 할당받지 못하고 대기하게 되는 상태를 Starvation라고 한다.
이 문제는 대기 시간이 긴 프로세스에게 우선순위를 부여하여 대기 시간이 길어질수록 우선순위가 높아지게 하는 방법을 통해 해결할 수 있다. 그중 Aging 기법은 SJF 알고리즘에서 버스트 타임이 높은 작업을 우선순위로 두어 문제를 해결하는 기법이다.
우선순위 스케줄링은 자원이나 시간이 많이 필요한 작업을 우선 순위로 두고 먼저 처리시켜 다음 작업을 진행할 때 자원이나 시간이 부족하여 대기 상태에 빠지지 않도록 한다. 이때 동일한 우선순위의 경우 해당 알고리즘을 통해서 처리하여 기아 상황에서도 공정한 작업 스케줄링이 가능하게 한다.
Round-Robin Scheduling
CPU 스케줄링에서 가장 일반적으로 사용되는 알고리즘이다.
시분할 시스템에서 사용되며 각 프로세스가 동일한 시간 할당량(Quantum)을 갖는다는 특징이 있으며 할당된 시간 이내에 작업이 끝나지 않으면 다른 프로세스에게 CPU를 양보하고 대기열의 끝으로 이동하는 과정을 반복한다.
* 시분할 시스템 : CPU 시간을 작은 단위로 분할하여 다수의 사용자가 동시에 컴퓨터를 사용할 수 있도록하는 기술이다.
주로 대화식 시스템에서 사용되는 것이 일반적이며 사용자가 프로세스를 시작하면 해당 프로세스는 대기열에 추가되는데 CPU는 대기열에서 가장 앞에 있는 프로세스에게 할당되고 일정한 시간 후에 다른 프로세스로 넘어가고 이 과정을 대기열이 비어 있을 때까지 반복한다.
FCFS와 마찬가지로 간단하며 쉽게 구현이 가능하지만 모든 프로세스에게 동일한 기회를 부여하기 때문에 더 공정한 스케줄링이 가능하다. 다만 할당된 시간이 작은 경우에는 자주 Context Switch이 발생하기 때문에 오버헤드 문제가 있을 수 있다. 또한 할당된 시간이 큰 경우에는 대기열에 있는 다른 프로세스들이 오랫동안 기다려야 하기 때문에 적절한 시간 할당량을 결정하는 것이 중요하다.
* Context Swtich : 문맥 교환, CPU가 현재 실행 중인 프로세스에서 다음으로 실행할 프로세스로 제어를 양도하는 과정
Memory
프로세스가 사용할 메모리 공간을 할당하고 메모리 공간을 관리한다.
운영체제에서 메모리 공간은 일반적으로 세 가지 방식으로 할당 및 관리된다.
Single Fixed Partition Allocation
단일 고정 분할 할당
메모리를 고정 크기의 분할로 나누고 각 분할을 프로세스에 할당한다.
분할 크기는 운영체제가 미리 정해놓은 것으로 프로세스의 크기가 이것보다 작아야한다.
단순한 방식이지만 메모리 이용률이 낮다는 단점이 있다.
Paing 기어
Variable Partition Allocation
가변 분할 할당
메모리를 동적으로 분할하며 프로세스에 할당하는 방식이다.
프로세스의 크기에 맞춰서 할당되기 때문에 메모리 이용률이 향상된다. 프로세스의 크기가 불규칙적이고 할당과 해제에 따른 Memory Fragment 문제가 발생할 수 있다.
Memory Fragment
메모리 단편화
메모리에서 사용 가능한 공간이 작은 조각으로 나뉘어 큰 용량의 프로세스가 할당되지 못하고 남는 작은 조각들이 늘어나는 문제를 말한다. 메모리를 효율적으로 사용하지 못하게 만들어 시스템 성능을 저하시키게 된다.
메모리 단편화는 Internal Fragment와 External Fragment 두 종류가 있다.
Internal Fragment
내부 단편화, 메모리 할당 시 요청한 프로세스크기보다 더 큰 메모리 공간을 할당하게 되어 할당된 메모리 공간 중 일부가 사용되지 않는 문제
External Fragment
외부 단편화, 메모리에서 사용 가능한 공간이 작은 조각으로 나뉘어 큰 용량의 프로세스가 할당되지 못하는 문제
이러한 메모리 단편화 문제를 해결하기 위해서 Paing과 Segmentation 기법이 사용된다.
Paging : 물리적인 메모리를 고정 크기의 블록으로 분할하여 가상 주소와 물리 주소를 매핑한다.
Segmentation : 프로그램을 논리적인 단위인 세그먼트로 분할하여 가상 주소와 물리 주소를 매핑한다. 페이징 보다 프로그램의 논리적 구조를 반영하기 쉽다.
Virtual Memory
가상 메모리
물리적인 메모리보다 큰 용량의 가상 메모리 공간을 프로세스에게 할당하여 사용하는 방식이다.
프로세스가 필요로 하는 부분만 메모리에 올려서 실행하고 나머지 부분은 디스크에 저장한다. 이 방식은 물리적인 메모리보다 큰 용량의 프로그램을 실행할 수 있게 되며 프로세스 간의 메모리 공유도 가능하다.
Storage
하드디스크 등의 저장장치를 관리하고 File System을 통해 파일을 관리한다.
* File System : 운영체제에서 파일과 디렉터리를 저장하고 검색할 수 있는 구조
파일이나 디렉토리를 저장하기 위한 블록의 할당, 디스크 공간 관리, 파일 접근 권한 관리, 파일 백업 및 복구 등의 역할을 수행하는데 일반적으로 파일 시스템은 파일과 디렉토리를 계층 구조로 구성하며 각 파일과 디렉터리는 고유한 이름을 가지고 있다.
디렉터리와 파일을 구분하는 특별한 기능을 수행하기 위한 파일을 사용하기도 하는데 이 파일은 파일 시스템의 일부이지만 일반 파일과 다른 속성을 가지고 있다. 예를 들어 리눅스에는 /dev 디렉터리에 하드웨어와 상호 작용하기 위한 특별한 파일들이 존재하는데 이러한 파일들은 일반 파일과는 달리 디바이스 파일로서 하드웨어 디바이스에 대한 인터페이스 역할을 한다. Windows에는 레지스트리 파일이 이러한 파일로 분류되며 운영체제 설정 정보를 포함하고 운영체제 및 애플리케이션의 구성을 제어하는 데 사용된다.
Input/Output
키보드, 마우스, 모니터, 프린터 등의 입출력 장치의 관리, 디바이스 드라이버를 통해 입출력을 처리한다.
Device Driver Management
장치 드라이버 관리
각각의 입출력 장치에 대해 운영체제는 해당 장치와 상호작용할 수 있는 드라이버를 관리한다. 이 드라이버는 해당 장치와 통신할 수 있는 인터페이스를 제공하며 운영체제와 프로그램 간의 데이터 전송을 담당한다.
I/O Request Management
프로그램이 입출력을 요청하면 운영체제는 이를 관리하며 각각의 입출력 요청에 대해 우선순위를 결정하여 처리한다. 이를 위해서 운영체제는 입출력 요청 큐를 유지하고 요청에 따라 적절한 장치를 할당하여 요청을 처리한다.
I/O Buffering
입출력 장치의 속도는 프로그램의 실행 속도와 차이가 있기 때문에 입출력 요청에 대한 응답을 기다리는 동안에는 다른 작업을 수행할 수 있도록 버퍼링을 수행한다. 이를 위해 운영체제는 입출력 데이터를 임시로 저장할 수 있는 입출력 버퍼를 유지한다.
Interrupt Process
입출력 작업 중에는 다양한 상황에서 인터럽트가 발생할 수 있는데 이를 위해 운영체제는 인터럽트 처리 루틴을 유지하여 각각의 인터럽트에 대해 적절한 처리를 수행한다.
I/O Protection
입출력 장치를 공유하는 다양한 프로그램이 동시에 실행될 경우 장치 접근에 대한 충돌이 발생할 수 있는데 이를 방지하기 위해 운영체제는 입출력 보호 기능을 수행하여 각각의 프로그램이 입출력 장치를 안전하게 사용할 수 있도록 보장한다.
입출력 보호 기능은 장치에 대한 접근 권한을 제어하는 기능으로 보안과 안정성을 유지한다. 사용자 프로세스가 입출력 장치를 임의로 사용하지 못하도록 하고 운영체제가 입출력 장치에 대한 접근 권한을 부여하고 사용자 프로세스는 해당 권한을 가지지 못한 상태에서는 장치에 접근할 수 없도록 한다.
하드웨어와 소프트웨어의 구성 요소, 기능, 상호작용 등을 설계하고 구성하는 방식이나 규칙으로 컴퓨터 시스템 전반에 대한 설계와 구조를 의미한다.
Von Neumann Architecture
폰 노이만 아키텍처
1940년대 말에 알렌 튜링과 존 폰 노이만 등이 제안한 아키텍처로 컴퓨터 시스템의 아키텍처 중 가장 널리 사용되는 구조 중 하나이다. 현대 컴퓨터 시스템의 대부분이 이 아키텍처를 기반으로 설계되었다.
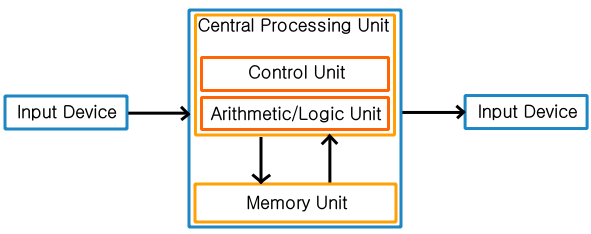
Von Neumann 아키텍처는 메모리, CPU, 입/출력 장치, 버스 등의 하드웨어 요소로 구성되며 이 중에서 CPU가 가장 핵심적인 구성 요소이다. CPU는 명령어를 순차적으로 처리하며, 프로그램의 명령어를 주기억장치에서 읽어와서 해석하고 실행한다. 따라서 명령어와 데이터를 모두 주기억장치에 저장하고 명령어와 데이터를 순차적으로 읽어오는 방식을 사용한다. 이를 '프로그램과 데이터의 저장공간이 동일하다'라는 의미에서 '단일 저장 장치(Single Memory)'라고 한다.
명령어와 데이터를 같은 메모리 공간에 저장하기 때문에 명령어와 데이터의 접근 시간이 동일하다는 것으로 명령어와 데이터를 주기억장치에서 읽어오는 시간이 줄어들어 전체적인 성능을 향상시킬 수 있다. 또한 프로그램의 수정이나 변형이 용이하다는 장점을 가진다. 하지만 주기억장치와 CPU 사이의 데이터 전송이 병목현상을 유발할 수 있으며 이를 해결하기 위해 캐시 메모리 등의 보조 기억장치를 사용하는 등의 방법이 고안되었다.
Havard Architecture
하버드 대학에서 개발되었다는 것에서 이름이 유래되었다.
Von Neumann 아키텍처와 달리 프로그램과 데이터가 동일한 메모리 공간에 저장되지 않고 각각 다른 메모리 공간에 저장한다. 이러한 구조를 가지는 컴퓨터 시스템은 두 개의 메모리 버스를 사용한다. 하나는 프로그램을 저장하는 코드 메모리 버스이고, 다른 하나는 데이터를 저장하는 데이터 메모리 버스이다. 이 두 개의 버스는 병렬로 동작하여 CPU가 동시에 코드와 데
이터를 읽을 수 있도록 한다.
이 아키텍처의 장점은 프로그램과 데이터가 각각 다른 메모리 공간에 저장되기 때문에 프로그램과 데이터를 동시에 읽을 수 있다. 따라서 프로그램 실행 시간이 더욱 빨라진다. 그리고 프로그램과 데이터를 분리하여 저장하기 때문에 데이터의 비인가된 접근을 막을 수 있어 보안성이 Von Neumann 아키텍처보다 높다. 하지만 각각 다른 메모리 공간에 저장되어 있기 때문에 프로그램 수정 시 코드 메모리와 데이터 메모리를 모두 수정해야하기 때문에 프로그램의 수정이나 변형이 불편하며 이러한 구조를 가지는 컴퓨터 시스템은 하드웨어 구조가 복잡하다.
Von Neumann 아키텍처와 Harvard 아키텍처 두 아키텍처의 차이는 명령어와 데이터를 메모리에서 어떻게 처리하느냐에 따라 달라지며, 이는 컴퓨터 아키텍처의 성능과 기능을 결정한다.
Instruction Set Architecture(ISA)
명령어 세트 아키텍처
컴퓨터에서 실행되는 명령어 집합과 해당 명령어의 동작을 정의하는 인터페이스 즉, 소프트웨어 개발자와 하드웨어 엔지니어 사이의 인터페이스 역할을 한다.
명령어 세트 아키텍처는 프로그래밍 언어와 컴퓨터 아키텍처 사이의 중개자 역할을 하며, 어떤 프로그래밍 언어를 사용하더라도 ISA에서 정의된 명령어 집합을 사용하여 작성된 프로그램은 모든 ISA 호환 컴퓨터에서 실행될 수 있다. 또한 ISA는 명령어의 크기, 명령어의 수행 방법, 레지스터의 개수와 종류, 주소 지정 방식 등과 같은 하드웨어 구성 요소를 규정하여, 하드웨어 제조업체들이 ISA를 준수하여 호환성을 보장할 수 있도록 한다.
RISC
Reduced instruction Set Computing
명령어의 수를 줄이고 명령어 실행 시간을 일정하게 유지하는 것에 초점을 두고 설계된 아키텍처이다.
CISC
Complex Instruction Set Computing
복잡한 명령어 집합과 다양한 주소 지정 방식 등을 지원하여 프로그래머가 작성한 코드의 길이를 줄이고 복잡한 작업을 더 쉽게 처리할 수 있도록 설계되었다.
Microarchitecture
ISA에서 정의된 명령어 세트를 하드웨어로 구현하는 방법에 대한 아키텍처이다. 마이크로 아키텍처는 ISA와 하드웨어 구현 사이의 중간 계층으로 ISA에 정의된 명령어 세트를 하드웨어에서 처리하기 위한 방법과 기술적인 세부 사항을 다룬다.
마이크로 아키텍처는 CPU의 내부 동작 방식을 설명하며 ALU, 레지스터, 캐시 등과 같은 하드웨어 요소들이 어떻게 조합되어 명령어를 실행하는지를 나타낸다. 이는 프로세서의 처리 속도와 성능에 직접적인 영향을 미친다.
예를 들어 Intel의 x86 아키텍처는 하나의 ISA를 여러 가지 버전의 마이크로 아키텍처를 통해 구현하는 방법이 다르며 이러한 버전에는 Pentium, Core, Atom 등이 있다.
ISA와 달리 마이크로 아키텍처는 하드웨어에 종속적이며 같은 ISA를 가진 두 개의 CPU라 하더라도 각각의 마이크로 아키텍처에 따라서 성능과 기능이 달라진다. 이러한 이유로 마이크로 아키텍처는 하드웨어 설계자들이 CPU를 개발할 때 매우 중요한 역할을 한다.
VLIW
Very Long Instruction Word Architecture
하나의 명령어로 여러 개의 연산 명령어들을 패킹하여 동시에 처리하는 방식을 사용하는 마이크로 아키텍처이다.
각 연산 명령어의 종류와 크기는 사전에 고정되어 있어야 하며 이렇게 하나의 명령어에 여러 개의 연산 명령어를 패킹하면 하나의 명령어를 실행하는데 필요한 클럭 사이클 수를 줄 일 수 있어 실행 효율성이 높아진다.
하지만 이러한 패킹 작업이 복잡하고 명령어에 들어갈 연산 명령어의 종류와 크기를 고정해야 하기 때문에 하드웨어 구현이 복잡해지고 설계 및 프로그래밍이 어렵다.
EPIC
Explicitly Parallel Instruction Computing
인텔에서 개발한 아키텍처로 VLIW의 한 종류이다. 명령어와 함께 해당 명령어를 실행하기 위한 하드웨어 리소스를 명시적으로 지정하여 병렬 처리를 구현한다. 이를 위해 명령어를 여러 개 묶어 하나의 Attention Point로 지정하고 해당 포인트에서 동시에 실행 가능한 명령어를 실행하는 방식을 사용한다. 이를 통해 프로그램 내의 병렬 처리 가능한 부분을 미리 식별하여 처리할 수 있기 때문에 성능 향상을 기대할 수 있다.
대표적인 예시로 인텔의 Itanium 프로세서가 있다. 명령어 세트가 복잡하고 처리 방식이 복잡하기 때문에 초기에는 호환성 문제 등으로 실패했지만 대용량 데이터 처리 등에서 높은 성능을 발휘하였다. 그러나 x86 아키텍처에 비해 생태계가 덜 발달하고 소프트웨어 호환성 문제도 있어 현재는 사용되지 않고 있다.
SIMD
Single Instruction Multiple Data
여러 개의 데이터가 동시에 처리하기 때문에 대규모 데이터 병렬 처리에 유리하다.
벡터 프로세싱이라고도 불리며 벡터 레지스터라는 별도의 레지스터를 사용하여 데이터를 저장하고 벡터 명령어를 사용하여 데이터를 처리한다.
예를 들어 4개의 데이터를 더하는 연산을 할때 일반적으로 4번의 덧셈 연산을 수행해야 하지만 SIMD 아키텍처에서는 한 번의 명령어로 4개의 데이털르 한꺼번에 연산할 수 있다. 따라서 SIMD 아키텍처는 더 빠르고 효율적인 데이터 처리가 가능하기 때문에 그래픽 카드나 디지털 신호 처리 등의 분야에서 많이 사용된다.
Intel의 MMX, SSE, AVX, ARM의 NEON 등이 이 아키텍처를 기반으로 한다.