에디터 버전 : 2021.3.28f1 (LTS)
Asset Pipeline
예전 에디터 버전에서는 Asset Pipeline 은 version 1, 2를 구분하여 선택하여 사용할 수 있었지만 최근 버전에서부터는 Asset Pipeline 2로 자동설정되며 선택할 수 없다.

에셋을 처리하는 과정에 대한 설정을 관리하는 항목들이다.
Remove unused Artifacts on Restart
재실행시 사용하지 않는 아티팩트들을 삭제할지 여부에 대한 토글로 기본으로 활성화된 상태이다.

유니티는 에디터가 실행될 때 라이브러리 폴더의 artifact 파일과 에셋 데이터베이스 엔트리에서 제거한다.
가비지 콜렉션의 형태로 이 설정을 비활성화하면 에셋 데이터베이스의 가비지 컬렉션이 비활성화된다.
즉 더 이상 사용하지 않는 수정된 아티팩트가 에디터가 재실행될 때에도 계속 보존되기 때문에 예상하지 못한 임포트 결과를 디버그 할 때 유용하다.
하지만 계속해서 사용하지 않는 데이터들이 쌓여갈 수 있기 때문에 일반적인 상황에서는 활성화해두는게 나을 것 같다.
라이브러리 폴더
유니티에 임포트 된 에셋은 두 가지 버전으로 구분된다. 하나는 사용자가 사용하기 위한 것이고 다른 하나는 유니티가 사용하기 위한 것이다. 이 유니티가 사용하기 위한 에셋은 프로젝트의 라이브러리 폴더에 캐시로 생성된다. 즉 라이브러리 폴더 내의 캐시들은 로컬에서 에디터가 빠르게 작업을 처리하기 위해 사용하는 정보들로 많은 정보들을 계속해서 저장하기 때문에 용량이 큰 편이다.
로컬에서만 필요한 이 정보들은 프로젝트가 켜질 때마다 확인하는 과정을 거치며 폴더가 없으면 다시 생성하기 때문에 프로젝트를 공유하는 경우에는 제외시켜도 되는 파일들이다.
Parallel Import
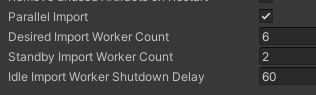
에셋을 임포트 할 때 동시에 진행하도록 하는 설정이다.

해당옵션은 기본으로 비활성화되어있고 이 경우 에셋을 순차적으로 임포트 하게 된다.
이 기능은 특정 유형의 에셋에서만 지원되며 에디터가 프로젝트 폴더에서 에셋이 새로 임포트 되거나 수정된 에셋을 감지하고 자동으로 임포트 할 때 발생하는 에셋 데이터베이스가 새로고침을 수행할 때만 실행된다. 이때 에셋은 하위 프로세스에서 임포트가 실행된다.
특정유형
- Texture Importer로 가져온 이미지 파일
- Model Importer 로 가져온 모델 파일
특정 유형은 임포트 시간이 오래 걸리는 두 가지로만 구성되며 현재 버전까지는 별도의 스크립터블이 가능한 API는 마련된
지 않은 상태이다.

이외의 유형은 해당 설정이 활성화되어 있어도 순차적으로 임포트 된다.
Desired Import Worker Count
병렬 임포트에서 사용할 작업 프로세스의 최적의 수
Standby Import Worker Count
쉬고 있는 상태에서도 유지시킬 최소의 작업 프로세스의 수
에디터에서 작업에 필요한 프로세스의 수가 최소보다 큰 경우 쉬고있는 프로세스를 중지시키고 시스템 리소스를 확보하도록 한다.
Idle Import Worker Shutdown Delay
쉬는 상태의 작업 프로세스를 종료할 때 대기하는 시간
또한 Edit > Preferences > Asset Pipeline에서 새 프로젝트에서 필요한 작업 프로세스의 기본 값을 제어할 수 있다.
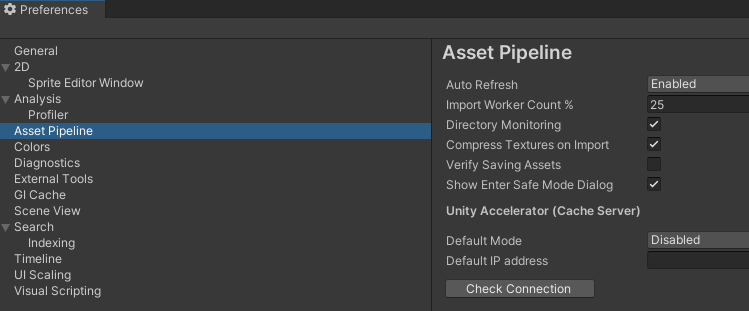
Import Worker Count % 의 값을 사용하여 Desired Import Worker Count 값을 할당할 수 있다.
이때 할당되는 값은 시스템에서 사용할 수 있는 논리 코어 수의 비율에 해당한다.
(16개의 논리 코어가 있다면 이중 25%를 할당하여 Desired Import Worker Count 값은 4가 할당된다.)
Cache Server (project specific)

Asset Pipeline 1 일 때 사용한 기능으로 버전 2에서는 기본으로 비활성화되어 있고 활성화할 수 없고 Unity Accelerator로 대체되었다.
Accelerator
팀 작업 속도를 높이기 위한 기능이다.
임포트 한 에셋의 사본을 유지하는 캐싱 프락시 에이전트이다. 팀이 동일한 네트워크에서 작업할 때 프로젝트 일부를 다시 임포트 할 필요가 없도록 하여 반복 시간을 줄일 수 있도록 돕는다.
Prefab Mode
프리팹 관련 설정

Allow Auto Save
프리팹 설정 시 자동으로 저장되는 기능을 활성화할지 여부를 정할 수 있다.
활성화된 경우 프리팹 수정 씬에서 자동 저장 기능을 사용할 수 있는 상태가 된다.


Editing Environments
프리팹을 수정하는 환경을 편집하는 기능을 제공한다.
Regular Environment
일반 프리팹을 편집하는 환경에서 사용하고자 하는 신을 할당하면 배경으로 사용할 수 있다.


UI Envrionment
UI 프리팹의 편집하는 환경에서 사용할 수 있다.


Graphics

Show Lightmap Resolution Overlay
씬의 드로우 모드 중에서 Baked Lightmap 모드에 체커보드 오버레이를 그린다.
여기서 타일 하나는 텍셀에 해당하며 라이트매핑 작업 시 씬의 텍셀 밀도를 확인할 수 있다.


Use legacy Light Probe sample counts
활성화 시 Progressive Lightmapper를 사용하여 베이크 할 때 고정된 라이트 프로브 샘플 수를 사용한다.
Direct Sample 64, Indirect Sample 2048, Environment Sample 2048


Enable baked cookies support
2020.1 이상의 프로젝트는 기본적으로 베이크 된 쿠키가 Progressive Lightmapper의 베이크된 광원과 혼합 광원에 대해 활성화된다. 이전의 경우 해당 부분이 비활성화되는데 이 옵션은 이전 버전과의 호환성을 위해서 제공되는 기능이다.
Cookie
특정 모양이나 색상의 그림자를 만들기 위해 광원에 배치하는 마스크로 광원의 모양과 강도를 변경한다.
쿠키를 통해 런타임 성능에 최소한 또는 전혀 영향을 미치지 않는 선에서 복잡한 조명 효과를 효율적으로 사용할 수 있다.


'Develop > Unity' 카테고리의 다른 글
| Input System 사용시 UI 상호작용 안될때 (0) | 2024.11.18 |
|---|---|
| 유니티 프로젝트 창 검색 활용 (0) | 2024.06.30 |
| Asset Serialization, Binary and Text (0) | 2024.02.14 |
| Project Settings - Editor #1 (Unity Remote ~ Default Behaviour Mode) (1) | 2024.02.14 |
| Project Settings - Audio (1) | 2023.05.12 |