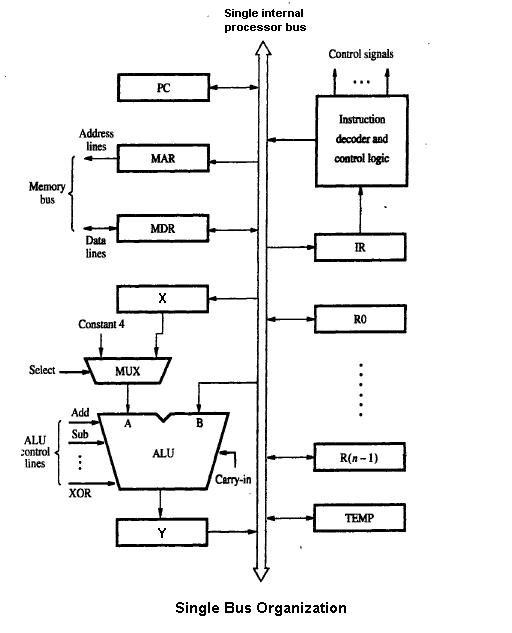
delegate
C/C++에는 함수를 가리키는 함수 포인터가 있다. 이를 사용하면 함수를 인수로 전달하거나 함수를 반환하는 등 다양한 방식으로 함수를 조작할 수 있는데 C#에서는 포인터를 직접적으로 사용할 수 없다. 그래서 C#에서 함수 포인터를 대신하는 개념으로 메서드를 참조하는 형식의 변수를 선언할 수 있도록 delegate를 사용한다.
delegate는 함수 포인터와 비슷한 개념으로 메서드에 대한 참조를 저장하여 메서드를 인수로 전달하거나 메서드를 반환하는 등의 작업을 수행할 수 있다. 메서드 자체를 하나의 변수로 다룰 수 있기 때문에 코드 자체를 참조하는 개념으로 볼 수 있다.
선언
delegate void DelegateDefault();
delegate int DelegateReturn();
delegate int DelegateReturnParam(int x, int y);
static void Main(string[] args)
{
DelegateDefault delegateDefault = new DelegateDefault(Print_1);
DelegateReturn delegateReturn = new DelegateReturn(Print_2);
DelegateReturnParam delegateReturnParam = new DelegateReturnParam(Print_3);
delegateDefault();
int result = delegateReturn();
int result_2 = delegateReturnParam(1, 2);
}
static void Print_1()
{
Console.WriteLine("Print_1");
}
static int Print_2()
{
int num = 2;
Console.WriteLine("Print_Out" + num);
return num;
}
static int Print_3(int x, int y)
{
int sum = x + y;
Console.WriteLine("Print_Out" + sum);
return sum;
}
선언된 델리게이트는 동일한 형식으로 선언된 메서드의 참조만 가능하다. 델게이트를 호출하면 참조중인 메서드를 호출하게 된다.
delegate chain
또한 델리게이트는 += 연산자를 통해서 동시에 여러 메서드를 참조할 수 있다.
delegate void DelegateChain();
DelegateChain delegateChain;
void Main(string[] args)
{
delegateChain += Print_1;
delegateChain += Print_2;
delegateChain += Print_3;
// ?.Invoke()를 사용하면 delegateChai이 null인 경우에 에러가 발생하는걸 방지할 수 있다.
delegateChain?.Invoke();
delegateChain -= Print_3;
delegateChain -= Print_2;
delegateChain -= Print_1;
}
static void Print_1() { }
static void Print_2() { }
static void Print_3() { }
참조중인 메서드 중에서 참조를 해제하려면 -= 연산자를 사용하면된다.
Anonymouse method call
델리게이트 체인을 활용해서 익명 메서드 호출도 가능하다.
void Main(string[] args)
{
delegateChain += Print_1;
delegateChain += Print_2;
delegateChain += Print_3;
delegateChain += delegate ()
{
Console.WriteLine();
};
delegateChain?.Invoke();
~
}
익명 메서드는 일회성으로 사용될 코드를 간단하게 작성할 때 주로 사용되며 특히 해당 코드가 특별한 용도를 제공하지 않거나 재사용될 필요가 없는 경우에 사용된다.
delegate는 대표적으로 이벤트 처리, 비동기 처리, 콜백에 사용된다.
Event
프로그래밍에서 이벤트는 어떤 특정한 조건이나 상황이 발생했을 때 이를 감지하고 처리하는 기능을 의미한다.
예를 들어 마우스 클릭, 키보드 입력 등이 이벤트이다. 이벤트 기반 프로그래밍(Event-driven programming)은 이러한 상황에서 반응하듯이 특정한 기능을 수행시키는 이벤트 기반으로 만드는 방식을 말하며 코드와의 상호작용으로 객체 간의 통신을 쉽게하고 객체의 라이프 사이클과 관련된 처리를 간편하게 할 수 있다.
Event Subscribe
이벤트 구독
일반적으로 이벤트를 다룰때 이벤트가 발생할때 동작시킬 기능에 해당하는 메서드의 할당과 참조는 외부에서 하더라도 이벤트의 발동은 델리게이트를 선언한 클래스 내에서 하는것이 권장된다.
외부에서 delegate에 메서드를 참조시키는걸 Subscribe, 참조한 메서드를 제거하는걸 Unsubscribe 라고 한다.
이렇게 외부에서 메서드를 참조하는 클래스를 Subscriber Class(구독자 클래스), 델리게이트가 선언된 클래스를 Publisher Class(게시자 클래스)라고 부른다.
public delegate MyDelegate();
// 게시자 클래스
public class MyPublisher
{
// 델리게이트
public MyDelegate MyEvent;
public void OnEvent()
{
MyEvent?.Invoke();
}
}
// 구독자 클래스
public class MySubscriber
{
private Publisher publisher = new Publisher();
public void Subscirbe()
{
// 구독
publisher.MyEvent += SomeMethod;
}
public void UnSubscribe()
{
// 해지
publicsher.MyEvent -= SomeMethod;
}
public void SomeMethod(){}
}
event keyword
델리게이트를 이벤트 목적으로 사용할때 event 키워드를 사용한다.
event 키워드를 통해서 delegate가 선언되면 해당 델리게이트는 외부 클래스에서 실행이 불가능하게 된다.
따라서 외부 클래스는 이벤트를 구독과 해지만 가능하며 이벤트의 호출은 선언된 클래스 내부 오직 한곳에서만 일어나기 때문에 안전하게 사용할 수 있게 된다.
선언
class EventListner
{
// 구독할 델리게이트
public delegate void EventHandler();
// event를 통해서 MyEvent는 내부에서만 호출 가능해진다.
public event EventHandler MyEvent;
public void OnMyEvent()
{
// ? : EventName null check
EventName?.Invoke();
}
}
class SubscriberClass
{
EventLister listner = new EventListenr();
public void Subscribe()
{
listner.MyEvent += SomeMethod
// Cannot Call delegate
lister.MyEvent?.Invoke();
}
public void SomeMethod(){}
}
event 제한자로 선언된 delegate를 외부 클래스에서 직접 호출을 시도하면 에러가 발생한다.
따라서 더 안전하게 이벤트를 구현할 수 있게 해주는 키워드라 할 수 있다.
Async
delegate의 비동기 작업은 일반적으로 멀티스레딩을 구현할 때 사용된다. 델리게이트를 통해서 메서드의 실행을 다른 스레드에게 위임하여 해당 스레드에서 비동기적으로 작업을 처리하고, 작업이 완료되면 해당 스레드가 호출한 스레드에게 결과를 알려준다. 이 작업 방식은 보통 결과를 필요로 하지 않는 작업을 빠르고 효율적으로 처리하기 위해서 사용한다.
보통 BeginInvoke()와 EndInvoke() 메서드를 활용해서 비동기를 구현한다.
* BeginInvoke : 해당 작업을 다른 스레드에서 비동기적으로 실행
* EndInvoke : 해당 작업이 완료되었는지 확인 후 결과를 반환
public delegate int AsyncMethodDelegate(int x, int y);
public class Calculator
{
public int Add(int x, int y)
{
return x + y;
}
// Add 메서드를 비동기적으로 실행
public void AddAsync(int x, int y, AsyncCallback callback)
{
AsyncMethodDelegate asyncMethod = new AsyncMethodDelegate(Add);
// 작업이 종료되면 callback
asyncMethod.BeginInvoke(x, y, callback, null);
}
}
public class Program
{
static void Main(string[] args)
{
Calculator calculator = new Calculator();
AsyncCallback callback = new AsyncCallback(CalculateCompleted);
calculator.AddAsync(1, 2, callback);
Console.ReadLine();
}
// callback 호출 함수
static void CalculateCompleted(IAsyncResult ar)
{
AsyncResult result = (AsyncResult)ar;
AsyncMethodDelegate asyncMethod = (AsyncMethodDelegate)result.AsyncDelegate;
int resultValue = asyncMethod.EndInvoke(ar);
Console.WriteLine("Result: " + resultValue);
}
}
Callback Function
콜백 함수는 다른 함수에서 인자로 전달되어 실행되는 함수를 말한다.
일반적으로 다른 함수의 작업이 완료된 후 호출된다.
만약 비동기적으로 실행되는 작업이 있을 때 해당 작업이 완료된 후 특정 동작을 실행시키고 싶다고 할때 여기서 콜백 함수를 사용할 수 있다. 비동기 작업을 수행하는 함수는 작업이 완료되면 콜백 함수를 호출하여 완료된 작업에 대한 처리를 수행하게 된다.
콜백 함수는 함수 포인터(delegate)나 람다식 등의 방식으로 전달될 수 있으며 주로 이벤트 처리나 비동기 처리 등에서 사용된다.
EventHandler가 대표적인 콜백 함수라 볼 수 있다.
// 버튼 클릭 이벤트 처리를 위한 콜백 함수
private void Button_Click(object sender, EventArgs e)
{
// 버튼이 클릭되었을 때 실행될 코드
}
// 이벤트 핸들러 등록을 위한 코드
button1.Click += new EventHandler(Button_Click);
버튼이 클릭되면 호출되는 Button_Click 메서드가 콜백 함수로 button1.Click 이벤트에 등록되어 클릭 이벤트가 발생하면 해당 콜백 함수가 실행되는 구조이다. 이렇게 delegate를 사용하여 콜백 함수를 등록함으로써 이벤트 처리와 같이 비동기적인 작업을 보다 효율적으로 처리할 수 있다.
Built-in delegate
C#의 내장형 delegate로 일반화된 형태의 델리게이트를 말한다.
매번 델리게이트를 선언하거나 만들 필요 없이 메서드를 매개변수로 전달하고 반환 값을 받을 수 있도록 하는것이 목적이다.
Action
Action은 C#의 내장 델리게이트 중 하나이다. 반환값이 없는 메서드를 참조할 수 있는 타입으로 매개변수를 받아서 반환값이 없는 메서드를 참조하는 기능을 한다.
Func
Func 또한 내장 델리게이트 중 하나로 입력 인자와 반환 값이 있는 일반적인 델리게이트 유형으로 반환 값을 가지는 메서드를 참조할 때 사용한다.
단순히 메서드를 전달 또는 메서드를 전달하고 반환 값을 받는 경우에는 Action이나 Func를 사용하는것이 코드를 간소화할 수 있다.
// Action을 사용하여 메서드를 매개변수로 전달하는 예시
public void PrintMessage(Action<string> messageAction)
{
messageAction("Hello, world!");
}
// 메서드를 Action으로 전달하고 실행
PrintMessage(message => Console.WriteLine(message)); // "Hello, world!" 출력
// delegate를 쓴경우
public delegate void MessageDelegate(string message); // 델리게이트 생성부터 필요
public void PrintMessage(MessageDelegate messageDelegate)
{
messageDelegate("Hello, world!");
}
// 메서드를 delegate로 전달하고 실행
PrintMessage(message => Console.WriteLine(message)); // "Hello, world!" 출력
//==============================================================================
// Func을 사용하여 메서드를 매개변수로 전달하고 반환 값을 받는 예시
public int GetStringLength(Func<string, int> lengthFunc, string str)
{
return lengthFunc(str);
}
// 메서드를 Func으로 전달하고 반환 값을 받습니다.
int strLength = GetStringLength(str => str.Length, "Hello"); // strLength에 5가 저장됩니다.
// delegate를 쓴경우
public delegate int LengthDelegate(string str);
public int GetStringLength(LengthDelegate lengthDelegate, string str)
{
return lengthDelegate(str);
}
// 메서드를 delegate으로 전달하고 반환 값을 받습니다.
int strLength = GetStringLength(str => str.Length, "Hello"); // strLength에 5가 저장됩니다.
불필요한 delegate의 선언부를 줄일 수 있게 된다..