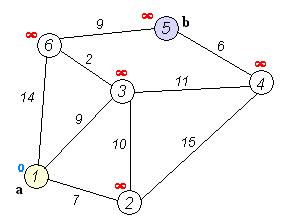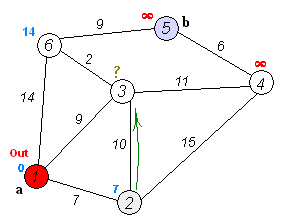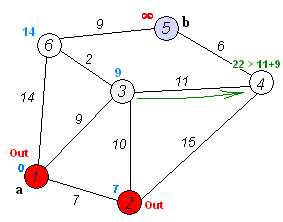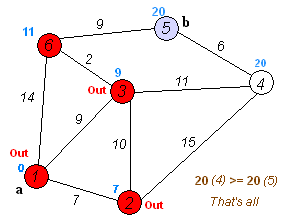
주어진 출발점에서 목표지점까지 가는 최단 경로를 찾아내는 그래프 탐색 알고리즘 중 하나이다.
최단 경로를 찾는다는 공통점을 가지지만, A*는 데이크스트라에 휴리스틱(Heuristic)이라는 개념을 추가하여 효율성을 높인 알고리즘이다. 본래 A 알고리즘이라고 불렸지만 적절한 휴리스틱에 따라서 최적의 알고리즘이 되기 때문에 A* 알고리즘이라 불린다.
데이크스트라와 관계
A*알고리즘은 데이크스트라 알고리즘의 확장 버전이라고 볼 수 있다. 데이크스트라에서 사용하는 시작점으로부터의 실제 거리 g(n)에 목표점까지의 예상 거리 h(n)라는 휴리스틱을 더한 값을 우선순위 기준으로 사용한다.
f(n) = g(n) + h(n)
g(n) : 시작점에서 현재 노드 n까지의 실제 비용
h(n) : 현재 노드 n에서 목표 노드 goal까지의 휴리스틱 비용(예상 비용)
f(n) : 시작점에서 n을 거쳐 goal까지 가는 총 예상 비용
휴리스틱 h(n)이 핵심 역할을 하며, 이 값이 얼마나 목표에 가깝게 추정하느냐에 따라서 A*의 효율성이 결정된다.
휴리스틱
가장 대표적으로 사용되는 두 가지 방법으로 맨해튼 거리(Manhattan Distance)와 유클리드 거리(Euclidean Distance)가 있다.
두 가지 방법 모두 특히 격자 기반의 길 찾기 문제나 2D/3D 공간에서의 최단 경로 탐색에 자주 활용된다.
맨해튼 거리(Manhattan Distance)
격자에서 한 점에서 다른 점까지 가로 또는 세로로만 이동할 수 있을 때의 최단 거리를 의미한다. 마치 도시의 블록을 따라 이동하는 것과 같다고 하여 맨해튼 거리 또는 택시 거리라고 불린다.
계산은 두 점 (x1, y1) , (x2, y2)가 있을 때 두 점 사이의 맨해튼 거리는 |x1 - x2| + |y1 - y2|이다.
이동이 수직(상하) 또는 수평(좌우)으로만 가능한 경우와 각 이동에 대한 비용이 모두 동일할 때 적합하다. (미로, 체스, 격자 등)
유클리드 거리(Euclidean Distance)
가장 일반적인 직선거리 개념으로 두 점을 잇는 가장 짧은 선의 길이이다.
두 점 (x1, y1) , (x2, y2) 사이의 유클리드 거리는 피타고라스의 정리를 사용하여 계산된다.
√ (x1 - x2)^2 + (y1 - y2)^2
대각선 이동이 가능한 경우, 이동 비용이 거리에 비례하는 경우에 사용하기 적합하다.
허용성
A* 알고리즘에서 휴리스틱 함수가 가져야 할 중요한 속성으로, 최단 경로를 정확하게 찾을 수 있는 여부를 보장하는 기준, 즉 A* 알고리즘의 정확성을 보장하는 핵심 조건이다.
허용 가능한 휴리스틱 함수는 어떤 노드에서 목표 노드까지의 예상비용이 실제 최단 거리보다 절대로 크지 않아야 한다.
h(n) ≤ 실제 최단 거리
h(n) : 현재 노드 n에서 목표 노드까지의 휴리스틱 비용
실제 최단 거리 : 현재 노드 n에서 목표 노드까지의 실제 최단 거리
A* 알고리즘이 최단 경로를 항상 찾을 수 있도록 보장하기 때문에 허용 가능한 휴리스틱을 사용하는 것이 중요하다.
최단 경로 보장
만약 휴리스틱이 실제 거리보다 과대평가한다면, 때때로 실제 최단 경로가 아닌 다른 경로를 최단 경로로 착각하여 탐색을 조기에 종료할 수 있다. 하지만 허용 가능한 휴리스틱은 항상 실제보다 같거나 작은 값을 예측하므로 항상 실제 최단 경로를 놓치지 않고 탐색하기 된다.
효율성과 균형
허용성은 정확성을 보장하지만, 너무 보수적인 휴리스틱은 A*가 데이크스트라처럼 넓은 영역을 탐색하게 만들어 효율성이 떨어질 수 있다. 따라서 이성적인 휴리스틱은 허용 가능하면서도 실제 최단 거리에 최대한 가까운 값을 예측하여, 최단 경로를 보장하면서도 탐색 효율성을 극대화하는 것이다.
예) 격자에서 가로/세로 이동만 가능하다고 가정할 때, 맨해튼 거리는 두 점 사이의 실제 최단 거리와 동일하거나 더 짧다. 장애물이 없는 최단 경로는 항상 맨해튼 거리보다 길거나 같을 수 없기 때문에 허용 가능한 휴리스틱이다.
예) 두 점 사이의 가장 짧은 직선거리는 유클리드 거리이다. 실제 경로가 장애물 때문에 직선으로 갈 수 없다면, 실제 경로는 유클리드 거리보다 길어질 수밖에 없으며 유클리드 걸리도 실제 최단 거리보다 과대평가하지 않으므로 허용 가능한 휴리스틱이다.
데이크스트라 알고리즘의 초기 형태는 우선순위 큐를 사용하지 않고, 일반적인 배열 또는 리스트를 사용하여 구현되었다. 이 방식은 매 단계마다 방문하지 않은 노드 중에서 시작점으로부터의 거리가 가장 짧은 노드를 선형 탐색하여 찾아낸다.
시간 복잡도
- 그래프에 V개의 노드가 있을 때, 매번 가장 짧은 노드를 찾기 위해 O(V) 시간이 소요된다.
- 가장 짧은 노드 선택과정을 총 V번 반복하기 때문에, 전체 시간 복잡도는 O(V * V) = O(V^2)이 된다.
플로우(일반 배열/리스트 사용)
기본 형태에서는 일반 배열/리스트를 사용하여 구현했는데 이 경우 그래프의 모든 노드를 방문하면서 각 노드를 방문할 때마다 짧은 거리를 찾는 과정이 필요한데 이때 V개의 노드가 있다면 모든 노드를 순회하는 작업이 O(V)의 시간이 걸리고 여기서 매 반복마다 O(V)의 시간이 소요되는 '가장 짧은 거리 노드 선택' 과정이 총 V번 반복되기 때문에 전체 시간 복잡도는 O(V^2)이 된다.
플로우
dist[] : 각 노드까지의 최단 거리를 저장, infinity 초기화
visited[] : 각 노드를 방문했는지 여부, false 초기화
start_node ( dist = 0 )